Up and Running With Version Control Systems
Every time someone enters the coding world he gets to hear terms like versions, VCS, GitHub and many more. Understanding of tools like Git and GitHub is important no matter you are working alone or in a team or your project is small or large because it helps a lot in maintaining a smooth workflow. Before going deep into VCS tools like Git one should know what a version control system is and why one should use it. By the end of this article, you will get answers to these questions.
What is Version Control?
It is just a management system which manages the changes in your projects until the end. These changes can be an addition of new files, modification of existing files or deletion of a file. It saves various snapshots known as Versions, of the projects which helps us to know which change was made when and by who made it. If a mistake is made, developers can turn back the clock and compare earlier versions of the code to help fix the mistake while minimizing disruption to all team members.
The figure below gives a web-based project example of a simple version control where we have saved 3 different versions of the projects at different times.
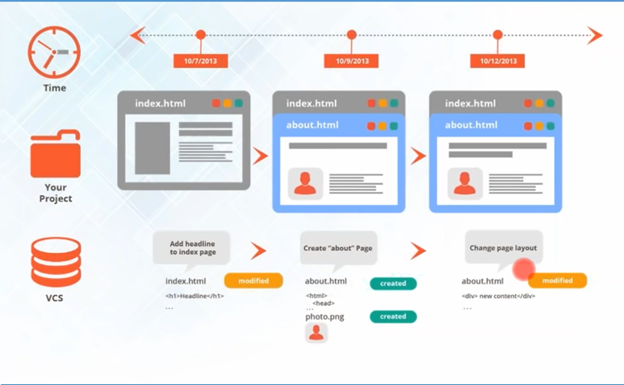
Version control is independent of the kind of project/ technology/framework you’re working with.
Also, don’t confuse a VCS with a backup or a deployment system. You don’t have to change or replace any other part of your toolchain when you start using version control.
Types of version control systems
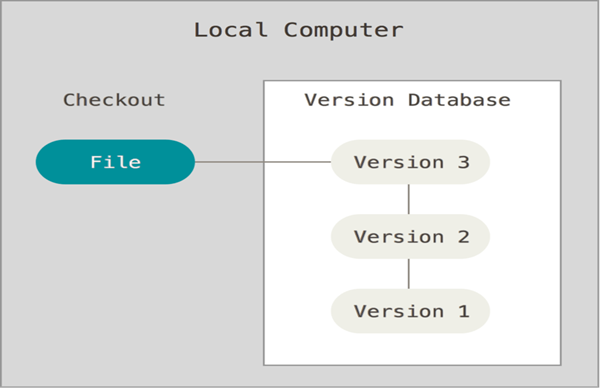
a) Local VCS:
Many people’s version-control method of choice is to copy files into another directory (perhaps a time-stamped directory, if they’re clever). This approach is very common because it is so simple, but it is also incredibly error-prone. It is easy to forget which directory you’re in and accidentally write to the wrong file or copy over files you don’t mean to.
To deal with this issue, programmers long ago developed local VCSs that had a simple database within the local machine that kept all the changes to files under revision control.
b) Centralized VCS:
The next major issue that people encounter is that they need to collaborate with developers on other systems. To deal with this problem, Centralized Version Control Systems (CVCSs) was developed. These systems, such as CVS, Subversion, and Perforce, have a single server that contains all the versioned files, and a number of clients that check out files from that central place.
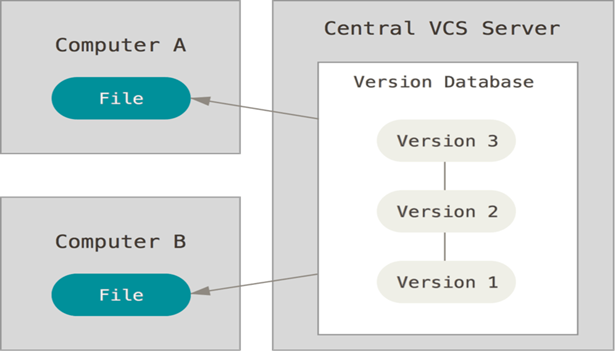
However, this setup also has some serious downsides. The most obvious is the single point of failure that the centralized server represents. If that server goes down for an hour, then during that hour nobody can collaborate at all or save versioned changes to anything they’re working on. If the hard disk the central database is on becomes corrupted, and proper backups haven’t been kept, you lose absolutely everything — the entire history of the project except whatever single snapshots people happen to have on their local machines. Local VCS systems suffer from this same problem — whenever you have the entire history of the project in a single place, you risk losing everything.
c) Distributed VCS:
In a DVCS (such as Git, Mercurial, Bazaar or Darcs), clients don’t just check out the latest snapshot of the files; rather, they fully mirror the repository, including its full history. Thus, if any server dies, and these systems were collaborating via that server, any of the client repositories can be copied back up to the server to restore it. Every clone is really a full backup of all the data.
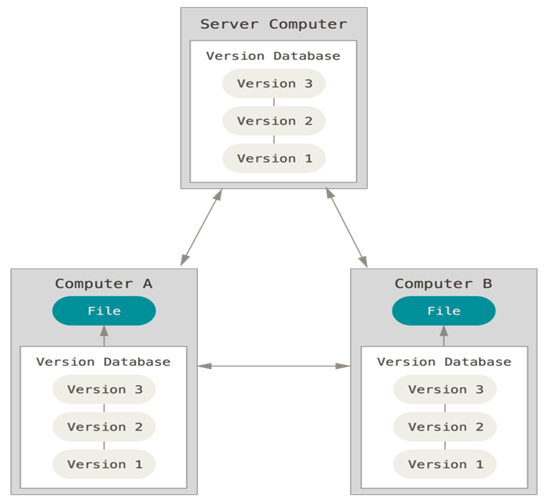
Furthermore, many of these systems deal pretty well with having several remote repositories they can work with, so you can collaborate with different groups of people in different ways simultaneously within the same project. This allows you to set up several types of workflows that aren’t possible in centralized systems, such as hierarchical models.
Why Version Control?
One might be thinking that he knows what are the changes he is making to his project and maybe those are for correcting the project, then why to use version control. But there are a number of things why we need it, so let us look at some of them.
a) Collaboration:
As most of the times, we work in a team so we have to know who is making what changes and to which file. For instance, if two or more persons are working on the same file then they might end up making different changes in the same file which will end up with a lot of errors.
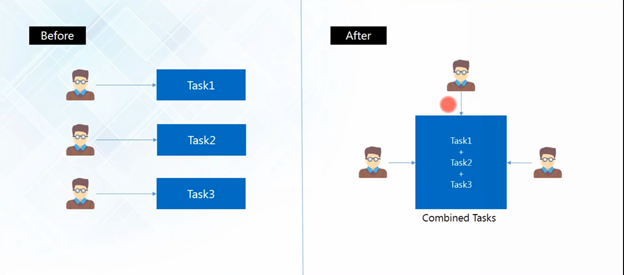
There VCS comes into play, with a VCS, everybody on the team is able to work absolutely freely — on any file at any time. The VCS will later allow you to merge all the changes into a common version. There’s no question where the latest version of a file or the whole project is. It’s in a common, central place: your version control system.
b) Storing Versions:

Saving a version of your project after making changes is an essential habit. But without a VCS, this becomes tedious and confusing very quickly:
• How much do you save? Only the changed files or the complete project? In the first case, you’ll have a hard time viewing the complete project at any point in time — in the latter case, you’ll have huge amounts of unnecessary data lying on your hard drive.
• How do you name these versions? If you’re a very organized person, you might be able to stick to an actually comprehensible naming scheme (if you’re happy with “acme-inc-redesign-2013–11–12-v23”). However, as soon as it comes to variants (say, you need to prepare one version with the header area and one without it), chances are good you’ll eventually lose track.
• The most important question, however, is probably this one: How do you know what exactly is different in these versions? Very few people actually take the time to carefully document each important change and include this in a README file in the project folder.
A version control system acknowledges that there is only one project. Therefore, there’s only the one version on your disk that you’re currently working on. Everything else — all the past versions and variants — are neatly packed up inside the VCS. When you need it, you can request any version at any time and you’ll have a snapshot of the complete project right at hand.
c) Branching and merging:
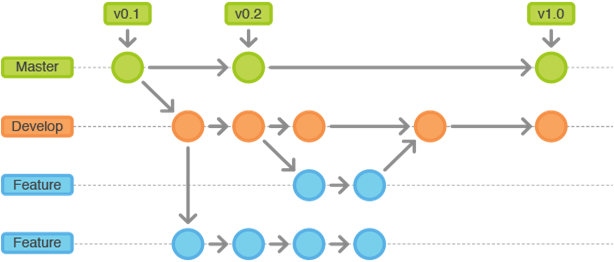
Having team members work concurrently is a no-brainer, but even individuals working on their own can benefit from the ability to work on independent streams of changes. Creating a “branch” in VCS tools keeps multiple streams of work independent from each other while also providing the facility to merge that work back together, enabling developers to verify that the changes on each branch do not conflict.
d) Backup:
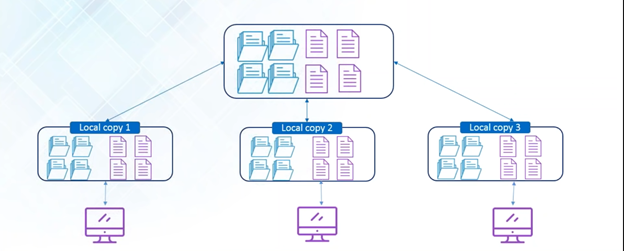
In VCS there is a central server where the entire project(source code) is saved as well as the local copies of the project that every developer has in his local machine (this is known as distributed version control system). In case the central server crashes or data gets corrupted, there are multiple local copies available locally with the developers and the system can be restored easily.
e) Tracability:

Being able to trace each change made to the software and connect it to project management and bug tracking software such as Jira, and being able to annotate each change with a message describing the purpose and intent of the change can help not only with root cause analysis and other forensics. Having the annotated history of the code at your fingertips when you are reading the code, trying to understand what it is doing and why it is so designed can enable developers to make correct and harmonious changes that are in accord with the intended long-term design of the system. This can be especially important for working effectively with legacy code and is crucial in enabling developers to estimate future work with any accuracy.
Comment below if you think something should be corrected.
You can find the PDF version here.
References:
